AI 翻译的核心是通过大语言模型(LLM)对海量多语言语料的统计概率计算,实现语义的迁移与重新生成。它与传统基于规则或纯统计的机器翻译不同,重点在于利用上下文理解来模拟人类语感,但在处理极高专业度或古语言时,仍会因概率预测而产生“幻觉”。
到 2026 年 3 月,AI 翻译已进化至“意译”阶段。但用户常发现,AI 既能写出文学级的段落,也会在专业术语上胡编乱造。这源于 LLM 的本质是预测下一个 token 而非真正理解知识。当训练集中某个生僻术语出现频率极低时,AI 会根据概率生成一个看起来正确但实际错误的词汇。
要发挥 AI 翻译的效能,应将其视为需要指令引导的翻译助理,而非一个黑盒。这意味着用户需要从简单的输入框翻译,转向基于 Prompt 工程的深度协作。
如何构建高精准度的 AI 翻译工作流

简单的“复制-粘贴-结果”流程极大浪费了 LLM 的潜力。工业级的工作流应包含:上下文注入、术语约束、多轮迭代润色。
1. 构建结构化指令
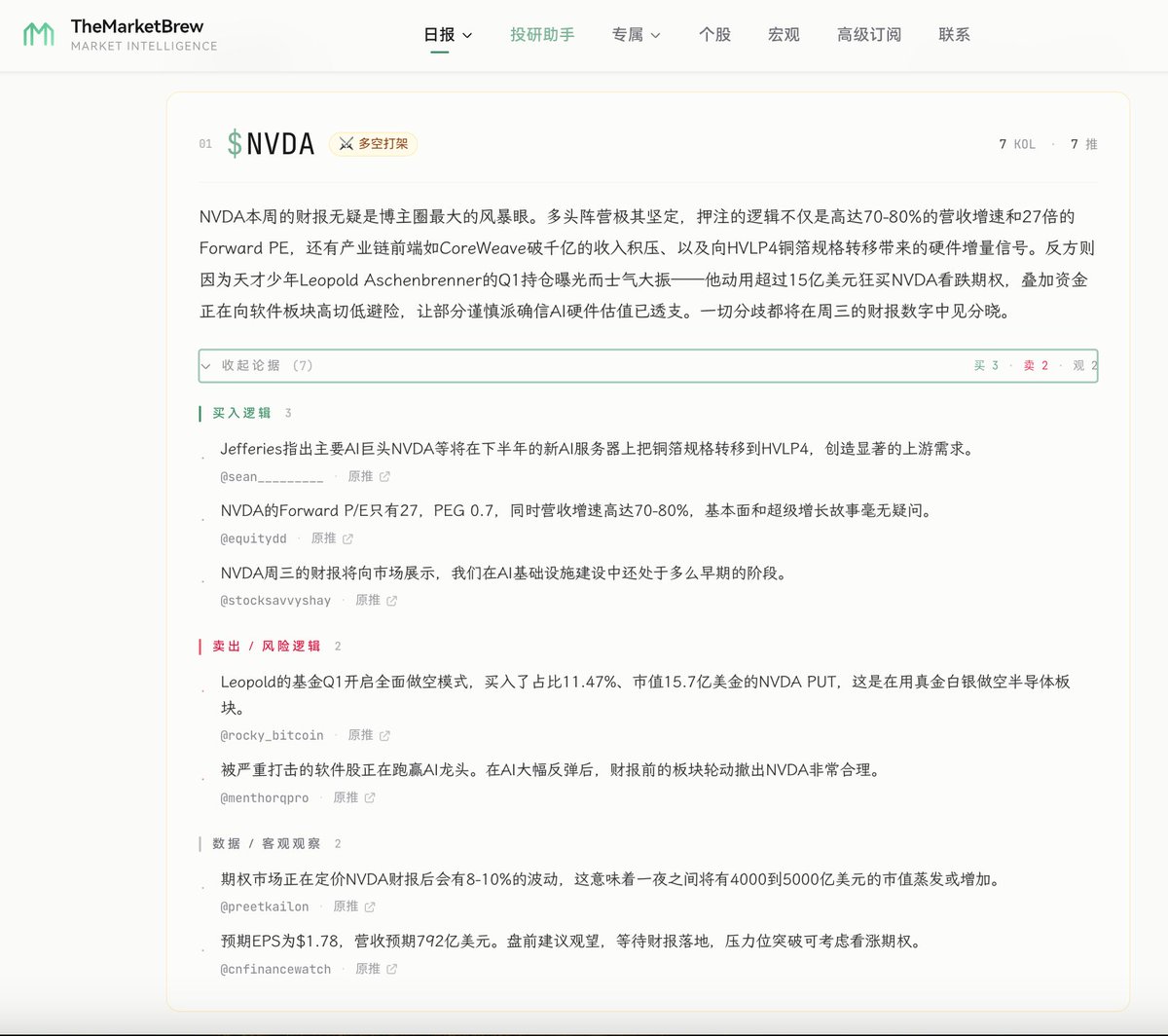
高效的指令应包含角色、任务、限制和格式,而非简单的请求。具体构建路径如下:
2. 提供上下文: 在翻译前,输入 3-5 个核心术语对照表(Glossary)。例如:Component $\rightarrow$ 组件,Hook $\rightarrow$ 钩子,State Management $\rightarrow$ 状态管理。
3. 设定限制: 明确要求“禁止使用‘不仅...而且’、‘总之’等典型的 AI 腔”,并规定在不确定专业术语含义时,保留原文并在括号中标注,禁止猜测。
4. 设定格式: 要求同时提供“对照翻译”和“流畅版”,方便在核对原意与优化语感之间快速切换。
这种方法能将专业术语的统一率从随机状态提升至 95% 以上。若发现错误,不要直接修改结果,而应在 Prompt 中加入新规则:“将 [错误词] 统一翻译为 [正确词]”,以确保后续文本的一致性。
2. 利用 API 实现工程化管理

通过 API 将 LLM 集成到翻译管理工具中,可以实现对大规模代码仓库文件或 JSON 语言文件的自动化扫描与填充,极大提升生产力。
- 环境准备: 安装 CLI 工具并配置
.env 文件,写入 API Key 和目标语言代码(如 zh-CN)。- 扫描定义: 通过特定注解标记需翻译的字符串,工具会自动抓取并发送给 LLM。
- 上下文传递: 在
system_prompt 中告知业务场景。例如:“这是一个金融交易 App 的界面文案,翻译必须极其简洁且符合金融监管措辞。”- 验证回填: 运行
translate 指令生成预览文件,经人工审查无误后,执行 commit 回写至 JSON。
针对 API Token 限制或请求超时,建议采用分批次(Batching)发送,每批处理 20-50 条短句,并设置 3 次重试机制。这能将原本需要一周的人工初译工作缩短至 10 分钟。
3. 复杂文本的多轮迭代润色法

面对文学作品、哲学论文或古语言,一次性生成容易产生语义偏差,建议采用“翻译-反译-对比-修正”的闭环法。
- 对比修正: 将原句、版本 A、版本 B 提交给 AI,询问:“版本 A 是否捕捉到了原作者的讽刺意味?请结合上下文给出三个不同选项,并解释语感差别。”
- 整体润色: 将修正后的文本组合,要求 AI 以特定风格(如“简练白话”或“半文半白”)统一全篇语调。
主流 AI 翻译工具横向对比
目前市场分化为三个主要阵营,用户应根据具体场景选择合适的工具:
| 工具类型 | 代表产品 | 优势 | 局限/风险 | 核心场景 |
|---|---|---|---|---|
| 通用大模型 | GPT-4o, Claude 3.5 | 意译能力强, 风格灵活 | 存在幻觉, 术语不稳定 | 创意写作、深度阅读 |
| 专业 AI 翻译平台 | DeepL, Google Translate | 词汇对齐精准, 术语库成熟 | 缺乏深层推理, 难处理隐喻 | 商务合同、快速阅读 |
| 集成式管理工具 | Intlayer, Lokalise AI | 工作流高效, 支持 API 驱动 | 技术门槛较高, 依赖流程 | 软件国际化(i18n) |
AI 翻译的边界与局限
尽管 AI 翻译能力飞跃,但在以下三个高风险场景中,过度依赖 AI 仍可能导致严重后果:
常见问题 FAQ
如何快速消除 AI 翻译的“机器味”?
可以通过在 Prompt 中加入特定的风格限制来解决。例如要求:“禁止使用‘总之’、‘不仅...而且’等连接词,尽量使用短句,模仿《经济学人》的叙事风格,并确保动词使用精准且具有力量感。”
API 翻译和网页端翻译在效果上有区别吗?
核心模型一致,但 API 允许你设置 temperature(温度值)。对于翻译这类需要稳定性的任务,建议将温度值设低(如 0.3),以减少随机性,提高术语的一致性。
行动建议
AI 翻译的重点已从“准确度”转向“场景融合”。对于普通用户,建议构建自己的“翻译指令库”。记录下能将学术论文转化为科普文,或能捕捉原著韵味的特定 Prompt,这种协作经验将成为核心竞争力。
对于专业翻译从业者,建议将重心从“语言转换”转移到“文化审计”。核心价值将不再是 A 语言变 B 语言,而是审计内容是否符合目标文化的禁忌、语境与共鸣。人文素养将比词汇量更重要。
现在可以尝试一个简单操作:下次使用 AI 翻译前,加上一句 “请先分析这段文本的语境、受众和隐含情绪,并在翻译时予以体现”。这通常能让输出结果的质感产生质的飞跃。