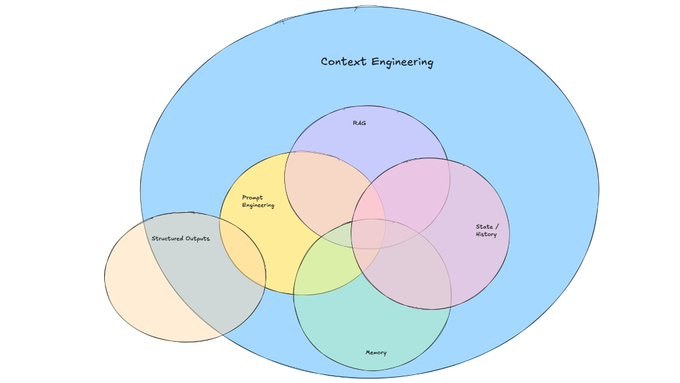
AI 翻译已从简单的词汇映射演变为能处理上下文、文化隐喻及专业逻辑的智能系统。目前的 AI 翻译并非单一工具,而是由神经机器翻译(NMT)与大语言模型(LLM)共同驱动的生态系统。
机器学习翻译(MLT)与生成式 AI 翻译存在本质区别。前者基于概率映射,输入相同,结果基本恒定;后者(如基于 GPT-5 或 Claude 4 架构的模型)具备随机性,能根据设定的语气和受众实时调整策略。这种从“翻译词句”到“翻译意图”的转变,是近三年最核心的变革。
翻译工作的性质正在改变。法律、医疗等高精度领域依然依赖人类,但翻译员的角色已从“创作者”转变为 AI 译文的“审核员”和“调优师”。
实现专业级产出不能仅靠对话框,而需要“提示词工程 + 术语库 + 反馈循环”的工作流。以下是具体实操方案。
第一步:构建领域特定语境(Contextual Grounding)
AI 翻译失败的主因是缺乏背景。同一词汇在法律合同与游戏对话中的含义截然不同。获得高精准度的前提是进行“语境喂养”。
参数配置方面,通过 API 调用时,建议将 Temperature(温度值)设为 0.3。过高会导致术语出现“幻觉”,0.3 能在保证流畅度的同时,维持术语的一致性。
针对长文本丢失语境的问题,可采用“分段翻译 + 状态传递”法:每段结束要求 AI 总结关键术语及译法,并在下一段开始前将其作为已知条件输入,避免前后译名不一。
第二步:建立动态术语库(Dynamic Glossary)同步

对于企业或学术翻译,术语一致性高于一切。AI 无法预知公司内部对特定功能的私有称呼。
使用 Trados 等专业工具时,应开启“Termbase Priority”选项,强制系统将术语库词汇注入生成序列。
若 AI 为追求语法顺畅而忽略术语,可追加二次修正指令:“请检查译文,在确保术语正确的前提下,优化句式使其符合中文母语习惯。”
第三步:实施多维度回译验证(Back-Translation Verification)
验证复杂译文最可靠的方法是回译,而非直接阅读。
1. 原文 A $\rightarrow$ 模型 1 $\rightarrow$ 译文 B
2. 译文 B $\rightarrow$ 模型 2(建议选择不同厂商,如 Claude 3.5) $\rightarrow$ 回译文 C
3. 对比原文 A 与回译文 C。
若 A 与 C 语义出现偏差,说明译文 B 存在信息丢失。此时将 A 和 C 同时输入给 AI,分析 B 的偏差环节并修正。注意回译时应关注“事实信息”而非“措辞”,避免过度修正。
AI 翻译工具选择指南
选择工具时应根据文本的性质(创意 vs 精确)和项目规模来决定。
| 工具类别 | 代表产品 | 核心优势 | 适用场景 |
|---|---|---|---|
| 通用大模型 | GPT-5, Claude 4 | 语感极佳,灵活度高 | 市场文案、邮件、创意写作 |
| 专业 CAT 工具 | Trados AI, MemoQ | 术语控制力极强 | 法律合同、工程手册 |
| 轻量级神经翻译 | DeepL, Google Translate | 速度快,简单句稳定 | 外刊速读、临时沟通 |
AI 翻译的局限性与风险
尽管 AI 能力飞跃,但在极高价值或极低容错率的场景中仍存在盲区。
首先是高情感价值的文学创作(如诗歌、意识流小说)依赖作者的生命体验和文化潜台词,AI 能翻译出“意思”但无法翻译出“灵魂”。
其次是极高法律风险的底层条文(如外交协议)中,微小偏差可能导致巨额损失。AI 无法承担法律责任,因此最终定稿必须由具备法律资质的人类专家签字背书。
最后是语料匮乏问题,AI 在处理极小众方言或濒危语言时常出现机械错误,此时人类