AI 翻译的核心逻辑与技术现状
AI 翻译是通过大语言模型(LLM)或神经机器翻译(NMT)将一种自然语言转换为另一种语言的技术。其核心逻辑是利用概率统计和语义向量空间预测最可能的对应文本,而非真正理解语言含义。到 2026 年 3 月,AI 翻译已能感知语境、风格与情感,但由于仍运行在统计概率框架内,处理极低频专业术语时仍存在“幻觉”风险,可能出现似是而非的误译。
目前的 AI 翻译分为两大技术路线
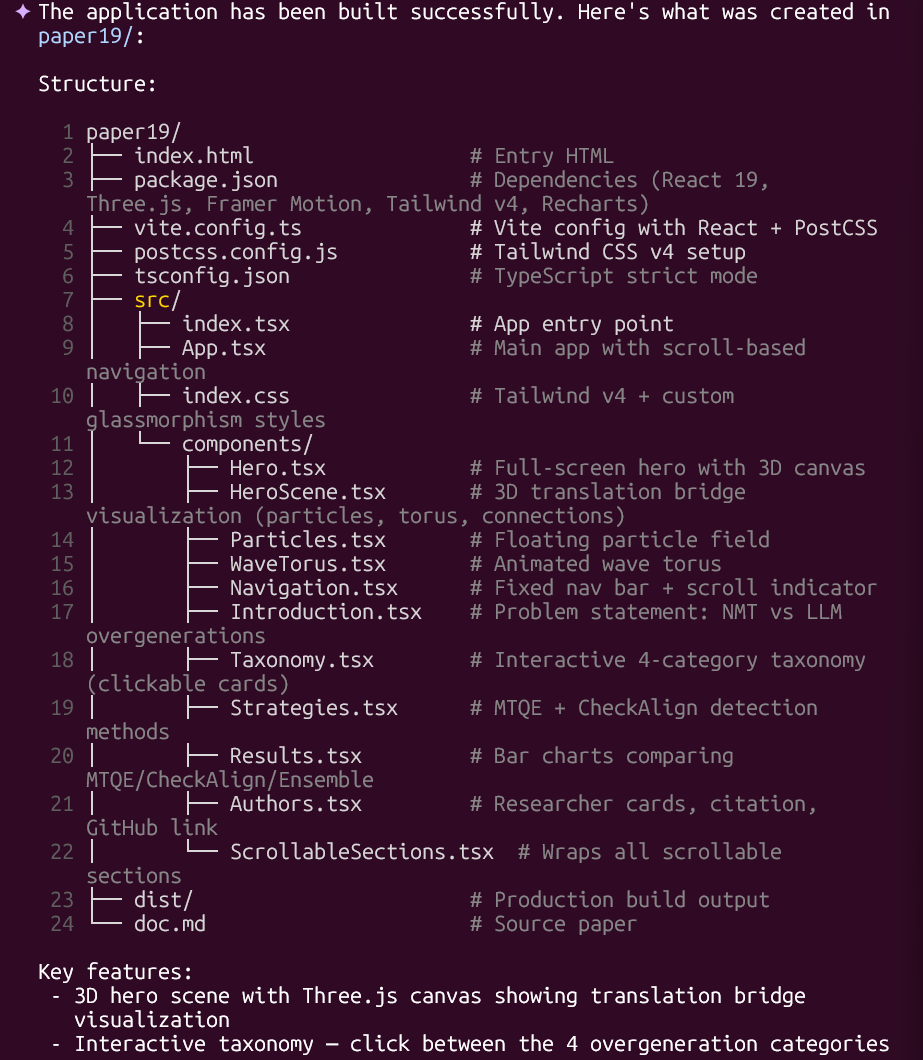
DeepL 和 Google Translate 为代表的传统 NMT 演进版速度极快,但在处理长文本的一致性上较弱;GPT-4o、Claude 3.5 和 Gemini 2-Flash 为代表的 LLM 翻译则具备强语境推断能力,可通过指令(Prompt)在学术、口语或商务风格间切换。
LLM 翻译依赖 Transformer 架构中的自注意力机制(Self-Attention)。模型在处理输入时会同时扫描全句,计算词与词之间的关联权重。例如,当“Bank”一词与“River”共同出现时,权重向“河岸”倾斜;若与“Interest”共现,则向“银行”倾斜。这种机制使 AI 能处理复杂的长难句,有效解决了早期的“翻译腔”问题。
专业级 AI 翻译的高效实操工作流
若要实现最高质量的产出,应采用“指令引导 -> 初译 -> 反向校验 -> 润色”的闭环流程。针对学术论文或技术手册等复杂文档,具体实操步骤如下:
第一步:构建上下文感知 Prompt

示例:“你是一位拥有 20 年经验的物理学译审,请将以下关于超导量子比特研究的文本翻译为中文。要求:1. 术语符合中国物理学会标准;2. 保持客观语气,不使用感叹词;3. 无法精准对应时在中文后括号标注原词。”
第二步:处理大规模 PDF 与分段翻译
第三步:执行反向翻译(Back-Translation)校验
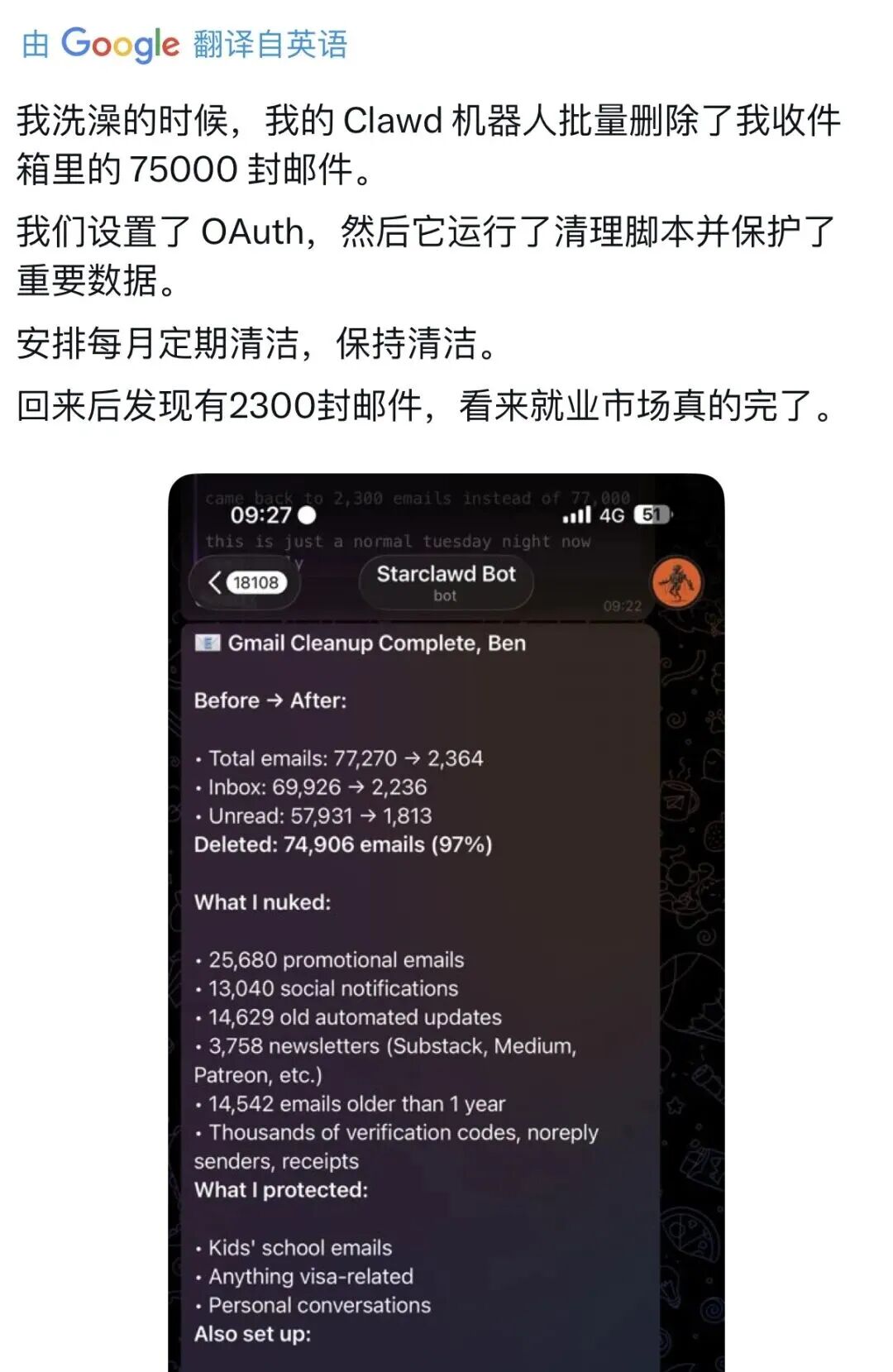
判断标准:若语义等价(如“high degree of stability”变为“very stable”)通常可接受;若出现限定词变更(如变为“stable in some cases”),则说明 AI 擅自添加了信息,必须人工干预。
第四步:风格微调与人工润色
工具选择与场景适用性分析
工具选择需基于具体维度权衡。

| 工具类型 | 代表工具 | 核心优势 | 最佳场景 |
|---|---|---|---|
| 传统 NMT | DeepL / Google Translate | 速度极快,基础翻译稳定 | 快速浏览、简单沟通 |
| 通用 LLM | Claude 3.5 / GPT-4o | 语境推断强,文学性高 | 深度创作、精准润色 |
| 长文本 LLM | Gemini-2-Flash | 超长上下文,性价比极高 | 学术文献、长篇报告 |
此外,云端 AI 存在数据隐私风险,涉及企业核心机密的文件,建议优先使用本地部署的 Llama-3 微调模型。
AI 翻译的局限性与不可依赖场景
AI 翻译并非万能,在以下三种场景中,人工审核是绝对不可或缺的:
2. 法律合同: 法律条文对“应当”与“可以”的界定极为严苛,AI 为了流畅度可能会模糊这种界限,导致法律风险。
3. 小众语言: 由于训练数据不足,AI 在处理方言或绝迹语言时极不稳定,常凭空捏造词汇。
AI 翻译真的能“理解”语言吗?
本质上 AI 翻译是一场概率游戏。它并不懂什么是“孤独”,但它知道英文 “lonely” 出现时,中文 “孤独” 的概率最高。因此,应将其定位为“高效的初稿生成器”而非独立的“翻译员”。
如何最快速地提升翻译质量?
建议将工作流优化为“AI 翻译 + 人工核验”。阅读外文文献可尝试 Gemini-2-Flash 的长文本功能;撰写对外邮件可用 Claude 3.5 润色。在正式发布前,花 10 分钟进行一次反向校验,这比依赖任何昂贵软件都可靠。