AI 降噪的技术底层与演进
AI 降噪是通过深度学习模型(如 CNN 卷积神经网络和 GAN 生成对抗网络)训练大规模“噪声-纯净”样本对,从而自动识别并剔除干扰信号,还原原始信息的技术。它已从简单的频率过滤演变为基于语义理解的智能重建,目前是图像处理和音频工程的工业标准。
AI 降噪的本质是“预测”与“重建”而非简单的“擦除”

AI 降噪的核心在于对信号的语义理解。传统算法(如高斯模糊或中值滤波)通过数学平均值处理,常导致画面模糊或声音发闷;AI 降噪则通过学习数百万组样本,能区分“噪点”与“皮肤纹理”或“人声泛音”。例如,AI 能将 ISO 8000 的高感照片处理至接近 ISO 100 的纯净度,但这实际上是 AI 基于经验对丢失细节的“脑补”。
多维应用:图像与音频的 AI 处理差异
在图像领域,AI 降噪依赖空间域和频率域的协同处理。DxO PureRAW 通过识别 EXIF 信息调用对应的镜头光学配置文件,在 Raw 文件的线性空间内去噪。因为该过程发生在信号被量化破坏之前,效果优于 JPEG 阶段的降噪。Topaz Photo AI 则更偏向生成式重建,利用 GAN 补全边缘线段,虽能提升锐度,但在商业摄影中易产生缺乏自然质感的“塑料感”。
音频 AI 降噪则聚焦于频谱掩蔽和源分离。UniConverter 或 Adobe Podcast 等工具基于 RNN(循环神经网络)或 Transformer 架构,将波形图转换为时频图,通过掩蔽矩阵(Masking)分离背景噪声(如空调风声、键盘声)与人声。目前的挑战在于平衡“清理力度”与“音调保留”:模型过强会导致人声出现类似水下说话的“电音感”,过弱则底噪明显。
专业工作流实操指南
图像 AI 降噪建议采用 DxO PureRAW 结合 Lightroom 的工作流
音频 AI 降噪可尝试 UniConverter 模块

主流工具对比分析

| 工具名称 | 核心优势 | 潜在风险 | 适用人群 |
|---|---|---|---|
| DxO PureRAW | 还原度最高,基于光学配置文件 | 价格较高(买断制) | 专业风光/商业摄影师 |
| Topaz Photo AI | 锐化效果极强,生成力高 | 易产生“塑料感” | 社交媒体创作者 |
| UniConverter | 处理速度快,价格亲民 | 极端噪声下易损音质 | Vlogger/企业培训 |
| Lightroom AI | 工作流集成度最高,便捷 | 极高 ISO 细节保留略逊 | Adobe 订阅用户 |
局限性与实践建议
AI 降噪并非万能,存在三个明确局限
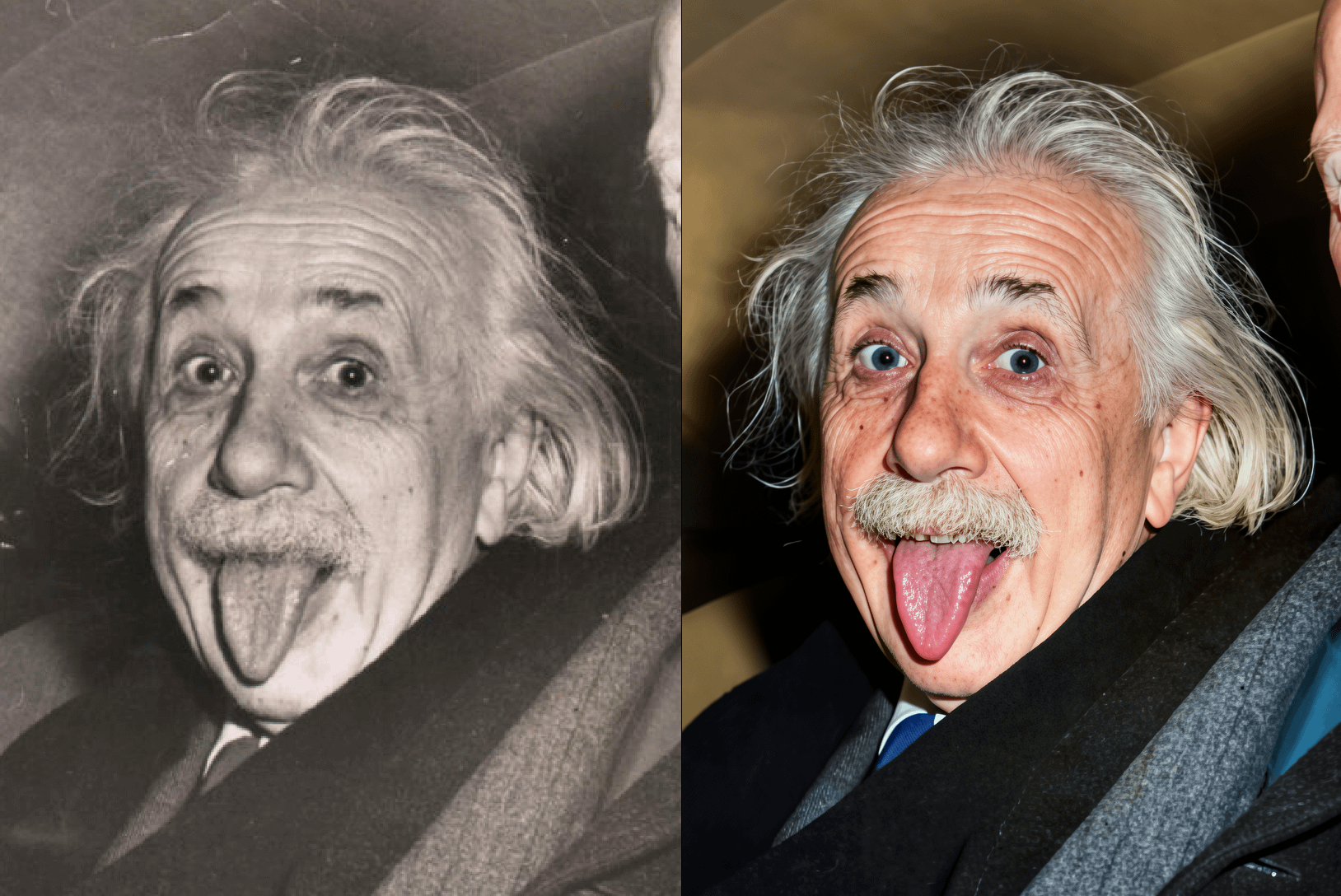
1. 伪影风险: 当 AI 无法识别特定模式的噪声时,可能将其误认为细节并强化,导致画面出现色块或音频出现诡异回响。
2. 计算成本: 高质量降噪对 GPU 显存要求极高,即便在 2026 年的硬件环境下,批量处理 6000 万像素照片仍有时间瓶颈。
3. 信号丢失不可逆: 若录音被巨大的爆破音覆盖或照片过曝导致像素饱和,AI 仅能通过模拟填充。这种模拟结果在法庭证据或医学影像分析等严谨领域不被认可。
Q:AI 降噪后照片出现“塑料感”怎么解决?
这通常是由于降噪强度过高导致纹理被抹平。建议降低降噪百分比(如维持在 40%-60%),并在后期软件中适量增加“颗粒”或“纹理”,以还原光学自然的质感。
Q:音频降噪后出现“水下说话”的声音是怎么回事?
这是典型的过度处理导致的相位失真或频谱空洞。建议降低人声增强等级,或尝试分段处理,确保在消除噪声的同时保留足够的高频泛音。
建议不要追求绝对的“零噪声”,而应追求“自然感”。影像保留 5% 的细微颗粒感会更具光学质感;音频保留少量环境音能增强临场感。建议使用同一段高噪素材在不同试用版软件中对比,寻找纯净度与真实感的平衡点。